INSTALACION:
RabbitMQ tiene soporte para varios sistemas operativos entre ellos Windows, Mac, Linux, BSD, UNIX, tambien se puede encontrar en repositorios Debian(apt) y RPM(Yum). Desde el lado de la nube, se puede encontrar varios proveedores especializados en SAAS, es muy compatible con kubernetes y ademas se puede encontrar una imagen en Dockerhub que en este caso voy a utlizar.
Lo primero sera descargar la imagen de RabbitMQ con el comando, eligiendo el
plugin management que desplegara una interfaz que permite controlar y un
monitorear lo relacionado a rabbitmq.
docker pull rabbitmq:3-management
Para desplegar el contenedo uso el comando
docker run -d --hostname bf-rabbit --name some-bf-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
Lo que se ejecuto es lo siguiente
run docker va a ejecutar una imagen
-d la ejecucion sera en background
--hostname: le dara un hostname que sera importante a la hora de subirlo a un proveedor cloud
--name: sera el nombre que se le dara al contenedor
-p publicara un servicio, en este caso en el puerto 15672 estara corriendo la interfaz grafica y 5672 esta el servicio de cliente de rabbitmq.
Y para finalizar la imagen de rabbitmq y especifica que se requiere tambien el plugin management.
Bueno ya que el entorno esta corriendo, se puede ingresar a la interfaz a
travez del navegador en el puerto 15672, en donde ingresar con usuario y
contraseña que por defecto es guest/guest.

En este espacio, se puede hacer seguimiento de las colas, crear usuario, muchas opciones que se abordaran en un proxymo post.

Ejemplos
RabbitMQ cuenta con soporte para distintos lenguajes, ya sea java,python,c#,js, entre otros, en este ejemplo se utilizara la libreria de python "pyka".
Productor.py

Primero importa la libreria pika.
Crea una conexion que recibe un parametro de conexion con una ip.
Crea un canal de conexion.
Declara un cola, dandole un nombre si no existe previamente.
Publicar un mensaje, usando un exchange por defecto, la ruta key que por el
momento usara el nombre de la cola y el mensaje que se quiere enviar.
Cerrar una conexion.
Consumidor.py

De manera muy similar al productor, importa la libreria, crea una conexion, crea un canal y una cola si no existia previamente. Luego crea una funcion que se utilizara por el momento para imprimir por pantalla el mensaje recibido, despues se define la cola en la que se enlazara, se llama la funcion que se creo anteriormente y los acuses de recepcion por defecto son manuales, el auto-ack facilita este flag .
Robin-Round Dispach
Imagina que estas haciendo muchas peticiones y que cada operacion se demora entre 2 - 3 segundos, de repente llegan 30 peticiones, esto representaria un retraso de cercano a un minuto y medio, la solucion es bastante sencilla, colocar mas instancias de consumidores, permitiendo escalar
Productor.py

Modificando un poco el ejemplo anterior, para hacer enviar un numero arbitrario de peticiones.
Para probarlo, es tan sencillo como abrir una nueva ventana y ejecutar otro Consumidor.py, por defecto RabbitMQ enviará mensajes a los consumidor de forma secuencial, esta distribucion de mensajes le llaman round-robin.
Message acknowledgment
Siguiendo el ejemplo, digamos que durante todo este proceso, uno de los consumidores muere, RabbitMQ lo marca para ser eliminado.
Para evitar que ese mensaje pre procesado muera, RabbitMQ implemente el ack, es enviado de vuelta por el consumidor para decirle a RabbitMQ que un determinado mensaje ha sido recibido, procesado y que RabbitMQ es libre de borrarlo.
Consumidor.py

Con esta peqeña modificacion, no se perdera nada , los mensajes se volveran a entregar
El ack debe ser enviado en el mismo canal que recibió la entrega. Los intentos de acuse de recibo utilizando un canal diferente darán lugar a una excepción de protocolo a nivel de canal.
Message durability
Que pasaria si por el contrario, es RabbitMQ el que se para o bloquea, hay que asegurar la cola o se perderan todos los mensajes. Para esto en la configuracion de la cola debe declararse como durable y aplicarse tanto a productor como a consumidor. Para evitar que la cola actual devuelva un error por pasarle otros parametros, se creara una nueva cola con otro nombre.
channel.queue_declare(queue='nuevo_saludo', durable=True)
Productor.py

Con esta modificacion marca como persistentes los mensajes, aunque no es una
garantia muy fuerte, es suficiente para estas pruebas. Si posblemente
les genera un error en los consumidores, posiblemente sea porque no se
ha modificado la cola del basic consume.
channel.basic_consume(queue='nuevo_saludo'...)
Fair dispatch
RabbitQM distribuye los mensajes de manera uniforme, pero esto trae consigo de que alguno de los consumidores va a tener una sobre carga de trabajo. Para solucionar esto hay que decirle a RabbitMQ que no envie mas mensajes hasta que termine la operacion.
Consumidor.py
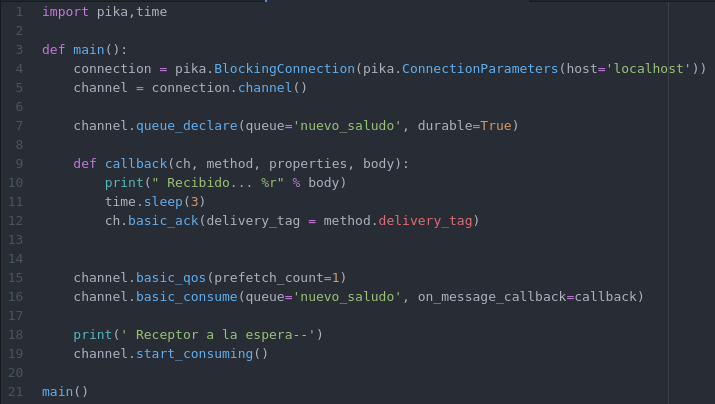
La pequeña modificacion dice a RabbitMQ que no le envie mas de un mensaje a la vez a los consumidores.








































{kind=link}
{kind=link}
{kind=link}
{kind=link}